

Twitter Sentiment Analysis
Introduction
Sentiment Analysis is the process of predicting whether a piece of information(usually text) indicates a positive, negative or neutral sentiment on a topic.
This project allows the user to input a keyword and gathers tweets based on it, then analyzes the sentiments of those tweets.
A classifier is Supervised if it is built on training corpuses containing the correct label for each input. The framework for supervised classification is described by the diagram shown below.
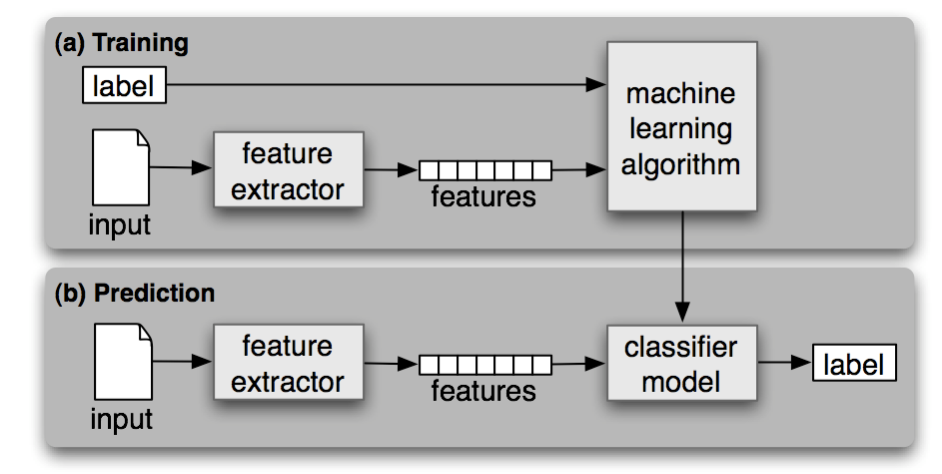
The work flow for this task will follow the shown framework. Taking our training set, a feature extractor converts each item into a feature set. These feature sets along with each input item’s label are put into our ML Algorithm to develop a model. During the prediction phase, the same feature extractor is used to convert the test set inputs into feture sets, these feature sets will have a label of Null or None. They are then put into the model which generates predicted labels to replace the Null or None
Getting Started
Let’s start with defining the packages required for fetching and reading/writing the data.
The Python Twitter API Wrapper Docs can be found here…
Python-Twitter Documentation
import sys
import twitter
from tqdm.notebook import tqdm
import json
import csv
import time
import random
import pickle
Next, we’ll define the packages required for the pre-processing of the data, as well as the classification.
We will be using NLTK(Natural Language Toolkit) for the heavy lifting. The package comes with predefined stopwords and punctuation.
Stop words are generally the most common words in a language, these along with punctuation do not assist predicting the sentiment and only take up valuable space. They are removed during pre-processing to reduce the computational load on the models.
import re
from nltk.tokenize import word_tokenize
from string import punctuation
from nltk.corpus import stopwords
import nltk
#!{sys.executable} -m pip install pattern
nltk.download('stopwords')
nltk.download('punkt')
Connecting to Twitter
The first step required is to connect to Twitter’s developer API. This is necessary to retrieve the data we would like to test our classifier on.
You can start by applying for access at…
Twitter Api
Once you have API credentials we can verify by caling VerifyCredentials()
As we can see, all my twitter information is returned in JSON response which includes a User object, so we’re good to go.
# Fun Python Trick, just print the import object to see full file path, helps with
# troubleshooting import issues.
print(twitter)
# init api instance
twitter_api = twitter.Api(consumer_key='CONSUMER_KEY',
consumer_secret='CONSUMER_SECRET',
access_token_key='ACCESS_TOKEN_KEY',
access_token_secret='ACCESS_TOKEN_SECRET')
twitter_info = twitter_api.VerifyCredentials()
json_object = json.loads(str(twitter_info))
print(json.dumps(json_object, indent=2))
<module 'twitter' from 'D:\\anaconda3\\lib\\site-packages\\twitter\\__init__.py'>
{
"created_at": "Mon Apr 16 03:05:50 +0000 2018",
"default_profile": true,
"description": "Ohio State Data Analytics | Android Dev",
"favourites_count": 22,
"followers_count": 12,
"friends_count": 57,
.
.
.
},
"statuses_count": 50
}
Building Test Set
Now that the API credentials have been verified, let’s write a function which will fetch tweets from Twitter based on a topic keyword.
def getTestSet(keyword):
try:
tweets = twitter_api.GetSearch(keyword, count = 100, lang='en')
print("Fetched " + str(len(tweets)) + "tweets for the term " + keyword)
return [{"text":status.text, "label": None} for status in tweets]
except:
print("Error")
return None
When running this code chunk, the user is prompted to enter the keyword which is then passed to our function getTestSet(keyword)
This returns 100 tweets based on that keyword.
We can peek at the first 4 below to get an idea of what we are working with.
As you can see, we’ve created a new object containing the tweet but also a label which as stated before will be temporarily labeled null until we perform the prediction.
search_term = input("Enter word: ")
testDataSet = getTestSet(search_term)
#print(testDataSet[0:4])
for x in testDataSet[0:4]:
print(json.dumps(x, indent=2))
Enter word: blm
Fetched 100tweets for the term blm
{
"text": "Florida police have released footage of the mass looting of a Walmart during the BLM race riots. https://t.co/Gvv91hMzcR",
"label": null
}
{
"text": "Imagine if Fox News was as upset about the lockdown protests as they are about BLM protests \ud83e\udd14 https://t.co/2U6BmjXJya",
"label": null
}
{
"text": "A stroke of genius cancelling the BLM protest. It gave the far-right centre stage to reveal who they are without an\u2026 https://t.co/pHiyVPxrri",
"label": null
}
{
"text": "@markgoldbridge They're gonna play with BLM on their shirts whilst playing football with said vulnerable group.\ud83d\ude02",
"label": null
}
Building Training Set
NOTE:
First time attempting this, I used this dataset Old Corpus however this was very skewed and contained ~4000 neutral classifications out of a dataset of 5000 points thus leaving only ~500 Positive and Negative labels remaining. Because of this the model predicted EVERYTHING as neutral. This was a lesson learned in the importance of checking your training sets to ensure balance.
I ended up finding a much more balanced training set which can be found here.
New Corpus
The only adjustments that were required was to convert the classification variable from an Integer(0,2,4) String representation to a text representation(Negative, Neutral, Positive).
The function created for building out the training set is shown here.
def buildTwitterTraining():
twitterTraining = []
with open('twitter_training.csv', 'r', encoding='cp1252') as csvfile:
so = csv.reader(csvfile, delimiter=',', quotechar="\"")
for ind, row in enumerate(so):
labelNum = row[0]
label = ""
if(labelNum == '0'):
label = 'negative'
elif(labelNum == '2'):
label = 'neutral'
else:
label = 'positive'
twitterTraining.append({"tweet_id":row[1], "text":row[5], "label":label})
Pretty Print first 5 tweets of training set to give us a preview.
twitterTraining = buildTwitterTraining()
print(json.dumps(twitterTraining[0:5], indent=2))
[
{
"tweet_id": "1467810369",
"text": "@switchfoot http://twitpic.com/2y1zl - Awww, that's a bummer. You shoulda got David Carr of Third Day to do it. ;D",
"label": "negative"
},
{
"tweet_id": "1467810672",
"text": "is upset that he can't update his Facebook by texting it... and might cry as a result School today also. Blah!",
"label": "negative"
},
{
"tweet_id": "1467810917",
"text": "@Kenichan I dived many times for the ball. Managed to save 50% The rest go out of bounds",
"label": "negative"
},
{
"tweet_id": "1467811184",
"text": "my whole body feels itchy and like its on fire ",
"label": "negative"
},
{
"tweet_id": "1467811193",
"text": "@nationwideclass no, it's not behaving at all. i'm mad. why am i here? because I can't see you all over there. ",
"label": "negative"
}
]
Text Preprocessing
The next step is pre-processing of the tweets…
This is a question of what matters and what doesn’t matter in Sentiment Analysis..
In NLP, text preprocessing is the practice of cleaning and preparing text data to something a computer can understand.
One of the major forms of pre-processing is to filter out useless data. In NLP, useless words (data), are referred to as stop words.
Using NLTK, we can look at the pre-defined english stop words
Tokenization is the act of breaking up a sequence of strings into pieces such as words, keywords, phrases, symbols and other elements called tokens. … Tokenization is used in computer science, where it plays a large part in the process of lexical analysis.
List of pre-defined stop words from NLTK package.
print(stopwords.words('english'))
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've",
"you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself',
'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their',
'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these',
'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having',
'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until',
'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during',
'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over',
'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all',
'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only',
'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should',
"should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't",
'' 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn',
"isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn',
"shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
The task of preprocessing can be nicely visualized with this image. Keep in mind that our preprocessing task will do a few extra things, since the domain we are working with is Twitter, which will also contain usernames, GIFs and hyperlinks.

We’ve created a class to handle the preprocessing, notice that all preprocessing can be done using just the
re and nltk packages.
class PreProcessTweets:
#Constructor
def __init__(self):
#Create list of pre-defined stoiterablepwords + extras
self._stopwords = set(stopwords.words('english') + list(punctuation) + ['AT_USER','URL'])
def processTweets(self, list_of_tweets):
processedTweets=[]
for tweet in list_of_tweets:
processedTweets.append((self._processTweet(tweet["text"]), tweet["label"]))
return processedTweets
# Process Tweet -> remove all information except the tweet text(lowercased, all punctuation removed)
def _processTweet(self, tweet):
#Convert all letters -> lowercase
tweet = tweet.lower()
# remove URL's
tweet = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', tweet)
#remove usernames
tweet = re.sub('@[^\s]+', 'AT_USER', tweet)
#remove hash from hashtag
tweet = re.sub(r'#([^\s]+)', r'\1', tweet)
# tokenize words and remove repeated characters (helloooooo -> hello)
tweet = word_tokenize(tweet)
word_list = []
for word in tweet:
if(word not in self._stopwords):
word_list.append(word)
return word_list
Now to do the actual preprocessing. We create our PreProcessTweets() class and pass in our trainingSet to the processTweets() function.
This returns a now processed training set which as discussed above will have stopwords,punctuation, usernames, url’s, etc. removed.
NOTE:
My twitterTraining set has 1,600,000 observations. As per NLTK documentation, this package does not handle large datasets well.

So, while it would be nice to have all those items contribute to the training, the package just won’t handle it. I’ve reduced the size to 20,000.
tweetProcesser = PreProcessTweets()
# preprocessedTrainingSet = tweetProcesser.processTweets(twitterTraining)
newTraining = []
newTraining.extend(twitterTraining[0:10000])
newTraining.extend(twitterTraining[1590000:1600000])
print(newTraining[0])
random.shuffle(newTraining)
train_set_pre = newTraining[:15000]
dev_test_set_pre = newTraining[15000:]
preprocessedTrainingSet = tweetProcesser.processTweets(train_set_pre)
preprocessedDevTestSet = tweetProcesser.processTweets(dev_test_set_pre)
print(len(preprocessedTrainingSet))
print(len(preprocessedDevTestSet))
15000
5000
Each observation is represented as below
(['awww', "'s", 'bummer', 'shoulda', 'got', 'david', 'carr', 'third', 'day'], 'negative')
- The tweet is has been processed and tokenized and so the object contains the tokenized tweet along with the attached label.
An important step taken above can be visualzed as so…

We’ve taken our development set TwitterTraining(subsetted into NewTraining(size 20,000)) and split that out into our Training Set(train_set_pre) and our Development Test Set(dev_test_set_pre). Each of these sets are passed through the preprocessing flow.
In the next section the training set will be used to train the classifier and then run that classifier on the Development Test set to gain the accuracy and also to generate a list of errors the classifier makes in prediction, which can then be used in error analysis if desired.
print("First Preprocessed Training Tweet: " + str(preprocessedTrainingSet[0]))
print("Last Preprocessed Training Tweet: " + str(preprocessedTrainingSet[19999]))
First Preprocessed Training Tweet: (['awww', "'s", 'bummer', 'shoulda', 'got', 'david', 'carr', 'third', 'day'], 'negative')
Last Preprocessed Training Tweet: (['happy', 'charitytuesday'], 'positive')
Now the same preprocessing to our test set.
preprocessedTestSet = tweetProcesser.processTweets(testDataSet)
Build a dictionary…
Compare every word in the training set against each tweet we have, creating a new binary feature which represents wether the word in our vocabulary is resident in the tweet or not
def buildVocabulary(processedTrainingSet):
all_words = []
for (words, sentiment) in processedTrainingSet:
all_words.extend(words)
# Distribution of the words in all_words
wordlist = nltk.FreqDist(all_words)
print(wordlist.most_common(15))
# take top 3,000 most common words
word_features = list(wordlist.keys())[:3000]
return word_features
def extract_features(tweet):
tweet_words = set(tweet)
features = {}
for w in word_features:
features[w] = (w in tweet_words)
#features['contains(%s)' % word] = (word in tweet_words)
return features
So now we have a dictionary called word_features this contains every word in the training set and the count of its occurences, for example (cat, 700), this says the word CAT has appeared in our training set 700 times.
#Build word features set
word_features = buildVocabulary(preprocessedTrainingSet)
[('...', 3583), ("'s", 2345), ("n't", 2240), ("'m", 1640), ('good', 1227), ('day', 1177), ('get', 1090), ('work', 1084), ('today', 1015), ('quot', 970), ('go', 922), ('like', 890), ('got', 848), ('going', 805), ('love', 746)]
featuresets = nltk.classify.apply_features(extract_features, preprocessedTrainingSet)
featuresets_dev_test = nltk.classify.apply_features(extract_features, preprocessedDevTestSet)
The 2 lines above build whats called a feature set. Each item in this feature set or vector represents a tweet from the training set.
Each vector item contains every word in the entire training set paired with a boolean which represents wether that word is present in the tweet, along with the pre-defined sentiment. The structure is displayed below.
[ listOf(every word in training set : true/false(present in tweet)), pre-defined sentiment(positive/negative) ]
Classification and Analysis
Now to train the bayes classifier on the training features we’ve just created
The most important and the shortest part of this project, training the classifier. NLTK makes this easy with a simple function. Since our training set contained 160,000 tweets, this may take quite a bit of time to train. I personally went to work out and get some coffee so I’m not sure on the exact amount of time.
It would be interesting however to find a python package that allows some kind of wrapper around functions which counts the time until completion.
NBayesClassifier = nltk.NaiveBayesClassifier.train(featuresets)
print(NBayesClassifier)
print(len(featuresets))
<nltk.classify.naivebayes.NaiveBayesClassifier object at 0x000002DBA5EDA2C8>
15000
Above we print the Classifier Object just to confirm it has been created and is in Memory, next we look at the length of our feature set. 15,000..the size of our Development Training Set
print("Classifier accuracy percent:",(nltk.classify.accuracy(NBayesClassifier, featuresets_dev_test))*100)
NBayesClassifier.show_most_informative_features(15)
Classifier accuracy percent: 77.27000000000001
Most Informative Features
throat = True negati : positi = 39.7 : 1.0
headache = True negati : positi = 38.3 : 1.0
easter = True negati : positi = 32.3 : 1.0
snow = True negati : positi = 27.9 : 1.0
died = True negati : positi = 24.3 : 1.0
spring = True negati : positi = 20.6 : 1.0
unfortunately = True negati : positi = 19.0 : 1.0
argh = True negati : positi = 18.3 : 1.0
lines = True positi : negati = 15.0 : 1.0
loss = True negati : positi = 14.3 : 1.0
22 = True negati : positi = 13.7 : 1.0
hates = True negati : positi = 13.4 : 1.0
dang = True negati : positi = 13.0 : 1.0
hurts = True negati : positi = 12.4 : 1.0
tweeps = True positi : negati = 12.3 : 1.0
Here we are gaining some metric on our classifier, testing the accuracy. As you can see, currently it’s at ~77%.
The show_most_informative_features() function is very useful. From the output we can see that for example
throat appears in a negative tweet almost 40x more than in a positive.
Examine Errors
Since of course the classifier will not have 100% accuracy, we now have the chance to examine the individual error cases where the classifier predicted the wrong label.
#Examine Errors
errors = []
for dict_item in dev_test_set_pre:
value = list(dict_item.values())
guess = NBayesClassifier.classify(extract_features(value[1]))
if(guess != value[2]):
errors.append( (value[2], guess, value[1]) )
^ Looking through the Development test set on which we performed the accuracy assesment, we generate a list of the tweets in which the wrong label was predicted. Each item in the developement set looks like this…
{'tweet_id': '2191372252', 'text': 'good morning world ', 'label': 'positive'}
print(errors[0])
print(len(errors))
('negative', 'positive', '306 letters to be sent out!! better start writing now ')
2531
After compiling that list of errors, we now can peek at the first one, this is saying
Correct Label = Negative, Predicted Label = Positive, Tweet Text = ....
We also see that it mispredicted ~2500 labels
for (tag, guess, text) in sorted(errors):
print('correct={:<8}, guess={:>8s}, text={:<30}'.format(tag, guess, text))
^ We can then print this list and inspect for patterns to help determine what additional pieces would allow the classifier to make the right decision, or alternatively which pieces are tricking the classifier into making the wrong decisions.
correct=negative, guess=positive, text= Heroes is losing it's momentum ): come on writers pick it up!!!
correct=negative, guess=positive, text= my housemaid.........oh I hate her :s I guess she has alzheimers she didn't even know MY NAME
correct=negative, guess=positive, text= not looking forward to my 10 hour shift tomorrow.
correct=negative, guess=positive, text=#3 woke up and was having an accident - "It's pushing, it's pushing!" he was crying because he couldn't stop from wetting his pants.
correct=negative, guess=positive, text=#Lahore @ EssexEating only been to Lahore. http://tinyurl.com/dbdjvz
correct=negative, guess=positive, text=#dreams Had to speak at night honoring michelle obama as fashion icon. Did so wearing her clothes. Got pee on them while changing.
correct=negative, guess=positive, text=#i36 Hope I'm feeling better by thursday, will be seriously annoyed if I'm ill over LAN
correct=negative, guess=positive, text="April SNOW showers. kill may flowers"
.
.
.
.
Testing Classifier
Now we are creating a vector of predicted sentiments for each tweet in the test set.
# classifing on the extracted feature vector for all the tweets in test set, which already have the sentiment labeled as NULL
NBResultLabels = []
for tweet in preprocessedTestSet:
NBResultLabels.append(NBayesClassifier.classify(extract_features(tweet[0])))
# MAJORITY RULE
print("Positive Labels: " + str(NBResultLabels.count('positive')))
print("Negative Labels: " + str(NBResultLabels.count('negative')))
if (NBResultLabels.count('positive') > NBResultLabels.count('negative')):
print("POSITIVE")
print("POSITIVE PERCENTAGE = " + str(100*NBResultLabels.count('positive')/len(NBResultLabels)) + "%")
else:
print("NEGATIVE")
print("NEGATIVE PERCENTAGE = " + str(100*NBResultLabels.count('negative')/len(NBResultLabels)) + "%")
Positive Labels: 79
Negative Labels: 21
POSITIVE
POSITIVE PERCENTAGE = 79.0%
The keyword parameter I used was blm which stands for Black lives matter, a pretty important topic at the time of this writing. It’s nice to see that ~80 of the 100 tweets we fetched from the API have been classified as positive.